AI Product Delivery
Mar 30, 2026
Terminal-First Development Needs a Staff: The Fictional Executive Panel Behind High-Leverage AI Delivery ⚙️📘🤖
Terminal-first development becomes dramatically more powerful when paired with markdown and a fictional executive AI staff. This article breaks down the highest-leverage roles, the key unknowns, and a phased model for governed AI delivery.

Terminal-First Development Needs a Staff: The Fictional Executive Panel Behind High-Leverage AI Delivery ⚙️📘🤖
Most builders still use AI like a faster intern.
That is not the ceiling.
At principal level, the more powerful model is to operate AI like a fictional executive staff: a governed panel of specialized decision-makers who review applications, challenge assumptions, classify risk, document findings, and force clarity before weak decisions harden into cost.
This is where terminal-first development becomes far more than a personal preference.
It becomes the ideal operating surface for a synthetic company.
At CAD Guardian, this model is especially potent because the work sits at the intersection of:
platform engineering
AI architecture
governance
application delivery
operational rigor
repeatable decision quality
And when that model is paired with markdown as the control plane, the result is a system that can produce unusual levels of speed, clarity, and execution pressure with very little waste.
This article covers the most important fictional employees in that staff, why markdown is central, what is known, what remains unknown, and how to execute the model in phases for maximum leverage.

The Core Idea
The fictional staff model works because most application failure is not caused by a lack of intelligence.
It is caused by:
unclear ownership
undocumented tradeoffs
weak escalation
poor reproducibility
absent decision history
shallow governance
fake confidence
unbounded experimentation
weak release discipline
no structured challenge function
A fictional executive staff solves that by introducing organized resistance.
Instead of asking one general AI for broad help, the application is reviewed by a company of specialists:
a CEO who asks whether the initiative matters
a Chief Architect who questions system shape
a Governance Architect who demands traceability
a Platform Director who insists on reproducibility
a Security Officer who looks for catastrophic exposure
an AI Architect who questions whether AI is warranted at all
a QA Director who attacks false confidence
a Product Lead who asks whether the workflow actually improves
a FinOps lead who ties technical choices to cost
This is not fantasy for its own sake.
It is a mechanism for generating synthetic organizational maturity.
Why Terminal-First Development Is the Right Foundation
Terminal-first development strips away decorative comfort and exposes operational truth.
That matters because governed AI systems perform better when the underlying application is explicit and inspectable.
A terminal-first workflow favors:
scripts over hidden clicks
logs over memory
reproducibility over improvisation
diffs over vague explanations
automation over ceremony
environment visibility over guesswork
evidence over opinions
That creates a better substrate for AI governance.
If the panel asks for proof, the terminal can generate it.
If the staff challenges a release, the terminal can show the build, test, dependency, or deployment state.
If governance asks what changed, version control and markdown can answer.
This is why the terminal is not merely a developer interface in this model. It is the source of operational evidence.
Why Markdown Is One of the Highest-Leverage Assets in the Entire System
Markdown is not a documentation convenience here.
It is one of the most important strategic assets in the operating model.
Markdown is the bridge between terminal output and institutional memory
The terminal generates raw evidence.
Markdown turns that evidence into durable, structured, AI-consumable knowledge.
It becomes the format through which the fictional staff can read, reason, compare, challenge, and record decisions.
Without markdown, every review risks becoming ephemeral.
With markdown, every review becomes reusable.
Markdown makes judgment portable
A strong markdown artifact can move cleanly across:
local repos
GitHub
pull requests
AI prompts
audit packets
runbooks
architecture records
release notes
handoff packages
internal knowledge systems
That portability is critical because the same truth must often serve multiple audiences:
engineering, governance, architecture, operations, and AI reviewers.
Markdown reduces translation loss
A recurring failure point in software delivery is that technical reality gets restated differently at every handoff.
Markdown minimizes that problem.
It can express:
staff charters
audit findings
decision logs
architecture diagrams in text form
release checklists
risk registers
policy standards
remediation plans
scorecards
P0/P1/P2 severity definitions
This makes it ideal for a system where both humans and AI agents need to consume the same operational truth.
Markdown is AI-friendly by default
AI systems perform better when the content is:
titled
segmented
hierarchical
predictable
easy to diff
easy to quote
easy to template
easy to regenerate
Markdown naturally supports all of that.
A giant paragraph blob weakens the panel.
A disciplined markdown packet strengthens the panel.
Markdown compounds over time
This is perhaps the biggest leverage point of all.
When markdown is used consistently, the fictional staff stops acting like isolated one-off agents and starts behaving like a company with memory.
It can inherit:
prior decisions
standard operating patterns
accepted architecture
rejected options
prior incident lessons
approved policies
recurring issue classes
severity scoring history
reusable remediation strategies
That is where the model becomes truly powerful.

The Most Important Employees in the Fictional Staff Panel 👔
A 24-agent company can provide breadth, but not every employee should have equal authority.
Some should advise.
Some should escalate.
A smaller core should have real gating power.
These are the most important employees.
1. Fictional CEO
Primary function: strategic coherence and final executive framing
This role asks:
Why are we building this?
What business system does it strengthen?
What happens if this succeeds?
What happens if this fails?
What deserves priority right now?
The CEO should not be buried in implementation detail.
Its job is to prevent the organization from optimizing for activity instead of leverage.
2. Chief of Staff
Primary function: operational conversion of insight into action
This is one of the highest-leverage roles in the whole system.
It produces:
decision summaries
action registers
owners
deadlines
unresolved issues
dependency chains
follow-up agendas
Without this role, the town hall becomes interesting but operationally weak.
3. Chief Architect
Primary function: guard system shape, boundaries, and long-term technical coherence
This role should gate:
service boundaries
API contracts
coupling risk
abstraction quality
platform fit
integration strategy
data flow shape
long-term maintainability
This is one of the strongest veto roles in the entire staff.
4. Principal Governance Architect
Primary function: enforce traceability, policy, control, and decision lineage
This role governs:
auditability
policy conformance
naming discipline
environment discipline
review sufficiency
decision logging
approval pathways
documentation thresholds
In serious delivery environments, this role is indispensable.
5. Principal AI Architect
Primary function: determine whether AI is justified, bounded, safe, and economically rational
This role asks:
Does this need AI at all?
Would deterministic logic outperform a model here?
What is the fallback path?
What is the model failure mode?
What happens when context is wrong?
How is prompt risk controlled?
How is model sprawl prevented?
This role protects the organization from expensive pseudo-sophistication.
6. Platform Engineering Director
Primary function: ensure the system can be built, operated, released, and restored repeatedly
This role governs:
terminal reproducibility
CI/CD
environment parity
secrets discipline
rollback readiness
deployment mechanics
local dev consistency
observability requirements
For terminal-first development, this is a core pillar.
7. Security and Trust Officer
Primary function: prevent breach, misuse, exposure, and trust collapse
This role governs:
authentication
authorization
secrets handling
injection risk
dependency trust
runtime permissions
external access surface
privileged tool use
This role should have hard P0 blocking authority.
8. QA and Reliability Director
Primary function: attack false confidence
This role governs:
acceptance criteria
edge cases
regression coverage
failure path testing
runtime assumptions
resilience scenarios
release confidence
observability of faults
This role often separates polished demos from production-grade systems.
9. Product Strategy Lead
Primary function: preserve market and workflow relevance
This role asks:
Who benefits?
What friction is reduced?
What speed is gained?
What premium value appears?
What does the buyer or operator experience improve?
It prevents platform-centric thinking from replacing customer value.
10. FinOps and Value Realization Officer
Primary function: tie technical design to financial consequence
This role inspects:
hosting cost
model cost
execution cost
support drag
labor reduction
margin improvement
cost of delay
cost of complexity
This role becomes more important as systems scale.
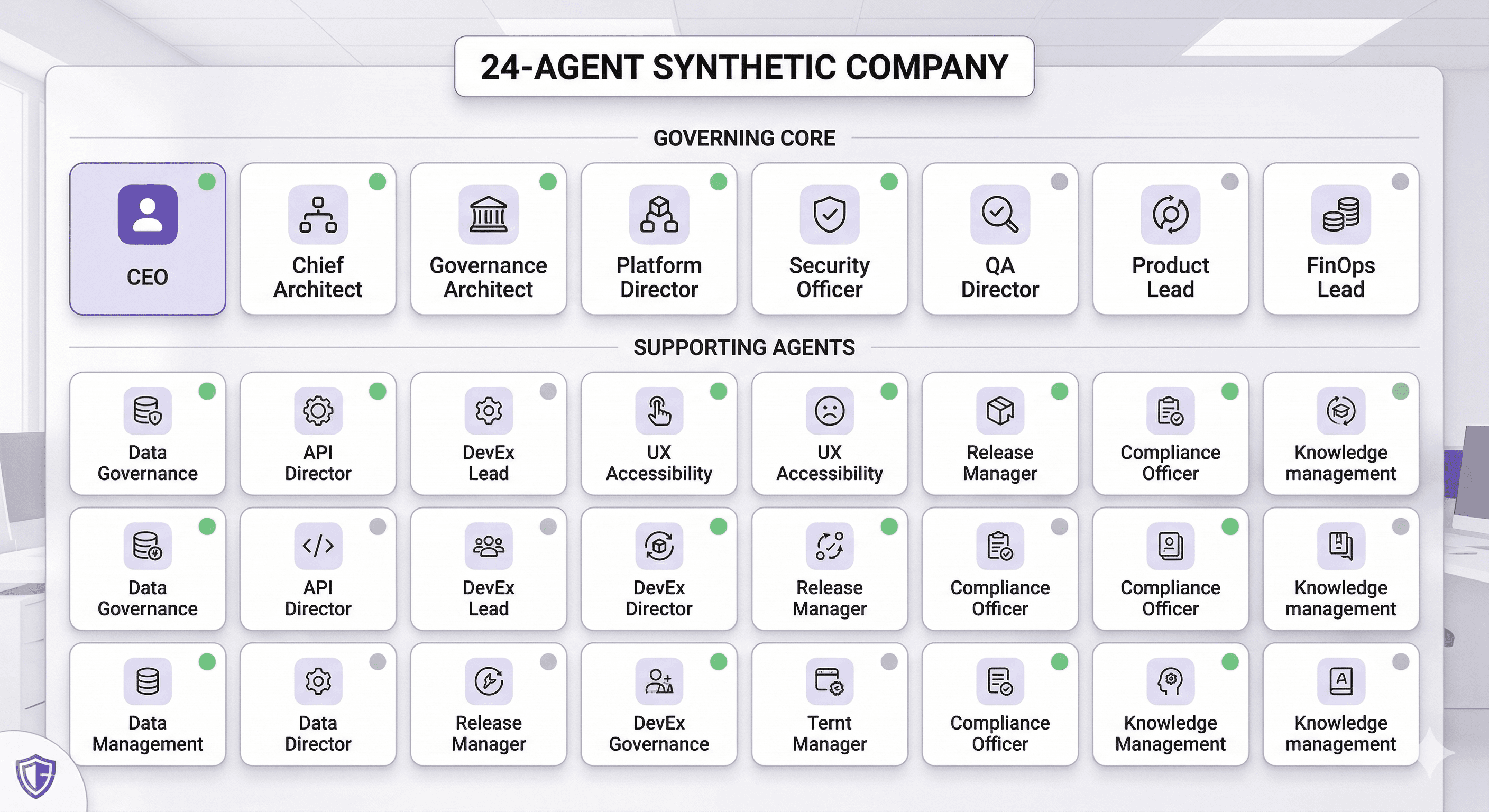
The Supporting 24-Agent Company
A practical fictional company may include the following supporting roles:
Data Governance Lead
API Integration Director
Developer Experience Lead
UX Accessibility Lead
Release Manager
Incident Commander
Compliance Officer
Documentation Strategist
Analytics and Telemetry Lead
Knowledge Management Librarian
Domain SME Agent
Customer Success Strategist
Performance Engineer
Sales Engineering Liaison
These roles matter.
But the core governing pressure typically comes from the top 10.
Which Roles Should Hold Veto Power?
This is one of the most important design decisions in the whole system.
Too many veto roles and delivery slows to a crawl.
Too few veto roles and governance becomes decorative.
The likely veto group is:
Chief Architect
Principal Governance Architect
Security and Trust Officer
Platform Engineering Director
QA and Reliability Director
These are the roles most directly tied to catastrophic error, structural weakness, and unsafe optimism.
The CEO should resolve escalated conflicts.
The Chief of Staff should record the outcome.
But not every role should be allowed to stop the train.
Knowns: What Is Already Clear
Several things are already highly defensible in this model.
Known 1: Terminal-first workflows increase audit quality
The more scriptable and reproducible the app is, the easier it becomes to generate evidence and challenge claims.
Known 2: AI staff models work better with narrow roles
A general-purpose AI can generate ideas.
A role-bound staff creates organizational pressure.
Known 3: Markdown dramatically improves AI governance
Markdown creates the shared memory layer that makes repeated audits sharper, faster, and more reusable.
Known 4: P0/P1/P2 tiers are essential
Severity separation prevents everything from feeling equally urgent.
Known 5: CEO-visible town halls improve alignment
The town hall format creates a narrative center of gravity where conflicting concerns can be surfaced and resolved.
Known 6: The highest value comes from structured disagreement
The real power of the panel is not agreement.
It is disciplined challenge.
Unknowns: Where the Highest Leverage Still Lives
This is where principal-level advantage is created.
Unknown 1: What is the ideal markdown structure for maximum reuse?
Too little structure creates ambiguity.
Too much structure creates bureaucracy.
The optimal level likely varies by:
app complexity
risk profile
domain sensitivity
release frequency
number of contributors
governance burden
Finding this balance is a serious leverage point.
Unknown 2: What evidence standard should each agent require?
A Security Officer should not want the same input format as a Product Lead.
Examples:
Security wants attack surface and secret handling evidence
Architecture wants dependency boundaries and contracts
Governance wants decision records and policy mapping
Platform wants scripts and deployment state
QA wants acceptance criteria and failure-path evidence
If evidence is undefined, audits become inconsistent.
Unknown 3: How should disagreements be staged?
You need a conflict protocol.
At minimum, define:
who presents first
who challenges
who can rebut
who can escalate
who can block
who makes final resolution
what gets permanently documented
Without this, the town hall becomes performance rather than governance.
Unknown 4: How should the auditors themselves be evaluated?
This is a hidden goldmine.
The staff itself should be scored on:
false positives
missed risks
duplicate feedback
clarity
actionability
business relevance
remediation usefulness
A fictional company that is never audited will eventually drift.
Unknown 5: Where should human override sit?
The human principal should not be dragged into every issue.
The highest-value override points usually involve:
irreversible architecture
strategic direction
policy exceptions
cost exposure
high-risk releases
unresolved cross-functional conflict
Designing those override points well is critical.
Unknown 6: Which workflows should never use AI?
This is a massive leverage question.
Many so-called AI problems are actually better solved by:
rules engines
parsers
validation logic
state machines
decision tables
schema contracts
scoring formulas
The stronger your AI practice becomes, the more aggressively this question must be asked.
Unknown 7: What should become permanent policy?
Recurring ambiguity should be harvested and converted into standards.
Examples:
prompt review requirements
release thresholds
markdown folder shapes
audit packet templates
agent output format rules
model selection rules
observability minimums
This is how maturity compounds.
Unknown 8: How much process is too much?
The model must remain high leverage.
If it becomes synthetic bureaucracy, the value collapses.
The goal is not to imitate a corporation.
The goal is to create just enough organized pressure that bad decisions surface early and good decisions become reusable.

The Markdown Assets That Matter Most 📘
These markdown files create disproportionate leverage.
Staff Charter Files
One file per agent containing:
mission
scope
non-goals
inputs
required evidence
output shape
escalation rights
veto status
Town Hall Agenda
A reusable format containing:
speaking order
app context
evidence list
key unresolved questions
severity routing
final decision protocol
P0 / P1 / P2 Severity Rubric
This should define:
issue types
business impact
technical impact
release consequences
required participants
expected urgency
Audit Report Template
A consistent structure for:
finding
severity
affected area
evidence
recommended remediation
owner
due date
escalation note
ADR Library
Architecture Decision Records preserve:
the decision
alternatives considered
tradeoffs
rationale
future consequences
Runbooks
These should cover:
setup
test
deploy
rollback
recovery
incident handling
environment restore
Policy Files
Markdown policies for:
AI usage
model approval
release governance
secrets handling
dependency control
observability minimums
documentation expectations
Executive Summary Memos
These support the CEO and Chief of Staff with:
what matters now
what changed
what blocks progress
what decision is required
what risk is accepted
Phased Execution Model for CAD Guardian 🚦
Phase 0 — Form the Fictional Company
Create the staff before scaling audits.
Deliverables
24-agent roster
role charters
authority matrix
veto rules
escalation paths
severity definitions
town hall template
Exit criteria
every role is bounded
veto authority is clear
outputs are standardized
Phase 1 — Establish Markdown as the Control Plane
Create the markdown backbone.
Suggested structure
Exit criteria
every critical review artifact has a markdown home
historical decisions are diffable
agents can consume consistent document structures
Phase 2 — Establish Terminal-First Evidence Generation
Everything important should be reproducible from CLI.
Examples
lint output
build output
test output
dependency reports
deployment logs
release notes
environment snapshots
telemetry exports
Exit criteria
claims can be supported with reproducible evidence
audits rely on generated artifacts, not memory
Phase 3 — Run P0 Audits
Focus on catastrophic exposure.
P0 examples
broken auth
exposed secrets
unsafe model/tool execution
missing rollback
corrupted business logic
no audit trail
deployment fragility
dangerous data handling
Required roles
Security
Platform
Governance
QA
Chief Architect
Exit criteria
no unresolved stop-ship items without explicit risk acceptance
Phase 4 — Run P1 Audits
Focus on structural weakness.
P1 examples
poor service boundaries
brittle prompts
weak fallbacks
monitoring gaps
cost opacity
platform inconsistency
undocumented business rules
architecture sprawl
Required roles
Chief Architect
AI Architect
Product Lead
FinOps
Platform
Data Governance
Exit criteria
structural issues are ranked and attached to a remediation path
Phase 5 — Run P2 Audits
Focus on optimization and enablement.
P2 examples
developer friction
UX rough edges
accessibility gaps
documentation weakness
onboarding burden
naming inconsistency
telemetry polish
workflow improvements
Required roles
DX Lead
UX Accessibility Lead
Documentation Strategist
Analytics Lead
Customer Success Strategist
Exit criteria
measurable friction reduction
improved maintainability
stronger operator experience
Phase 6 — Hold the Fictional CEO Town Hall
This is where the company becomes operational.
The town hall should answer
What matters most now?
What must be fixed first?
What risks are accepted?
What tradeoffs remain unresolved?
What is the next 30/60/90 day motion?
Outputs
CEO memo
Chief of Staff action register
ranked backlog
unresolved risk ledger
release confidence statement
Exit criteria
priorities are explicit
conflict is resolved or escalated
institutional memory is updated
Phase 7 — Audit the Staff
This is the advanced move.
Review
which agents drive the highest ROI
which roles miss critical issues
which outputs are repetitive
which markdown formats underperform
which veto points help or hinder velocity
Exit criteria
the fictional company improves its own governance engine
Recommended Power Ranking for Maximum Leverage
If the goal is maximum practical impact, the most important fictional employees are likely:
Chief Architect
Principal Governance Architect
Platform Engineering Director
Security and Trust Officer
QA and Reliability Director
Principal AI Architect
Chief of Staff
Fictional CEO
Product Strategy Lead
FinOps Officer
That group governs the majority of meaningful risk, execution quality, and system durability.
The broader 24-agent company adds perspective.
This core group determines whether the operating model is actually strong.
Why this matters for serious builders
If you are building apps, platforms, AI products, integration systems, or governance-heavy workflows, the challenge is rarely “can I produce code?”
The real challenge is:
can I produce disciplined execution
can I surface unknowns early
can I preserve decision quality under speed
can I build systems that remain governable as complexity grows
That is what this model is for.
CAD Guardian position
At CAD Guardian, fictional AI staff models are not a novelty.
They are a practical response to a real problem:
how to create institutional-quality review pressure, memory, and governance in environments that need to move fast without becoming reckless.
Operating thesis
The leverage does not come from AI alone.
It comes from combining:
terminal-first evidence
markdown-backed memory
role-specialized fictional staff
severity-based auditing
CEO-visible executive resolution
That combination turns scattered intelligence into an operating system.
Final Word
The strongest version of this model is not about pretending AI agents are employees.
It is about building a system where:
authority is explicit
evidence is reproducible
markdown carries memory
disagreement is structured
audits create movement
governance compounds
technical decisions become harder to make poorly
That is what high-leverage principal-level execution should look like.
And for teams serious about platform engineering, AI architecture, and governance, that may be one of the most important shifts available right now. ⚙️📘
Reusable Markdown Folder Structure
Want this turned into a full CAD Guardian content pack?
Next step is to generate the companion assets with your favorite ai:
homepage summary
LinkedIn post
24-agent staff charter pack
CEO town hall markdown template
P0/P1/P2 audit templates
markdown operating system starter repo structure
Happy coding!
www.tsmithcode.ai